최신버전MLA-C01높은통과율공부자료덤프로AWS Certified Machine Learning Engineer - Associate시험을한방에패스가능
Wiki Article
그 외, Pass4Test MLA-C01 시험 문제집 일부가 지금은 무료입니다: https://drive.google.com/open?id=1KmAdqdWcD2rHi4aeSptQR-Zx611LvaAZ
Pass4Test의 완벽한 Amazon인증 MLA-C01덤프는 고객님이Amazon인증 MLA-C01시험을 패스하는 지름길입니다. 시간과 돈을 적게 들이는 반면 효과는 십점만점에 십점입니다. Pass4Test의 Amazon인증 MLA-C01덤프를 선택하시면 고객님께서 원하시는 시험점수를 받아 자격증을 쉽게 취득할수 있습니다.
Amazon MLA-C01 시험요강:
| 주제 | 소개 |
|---|---|
| 주제 1 |
|
| 주제 2 |
|
| 주제 3 |
|
| 주제 4 |
|
Amazon MLA-C01시험대비 최신 덤프공부, MLA-C01인증시험대비 공부자료
최근 IT 업종에 종사하는 분들이 점점 늘어가는 추세하에 경쟁이 점점 치열해지고 있습니다. IT인증시험은 국제에서 인정받는 효력있는 자격증을 취득하는 과정으로서 널리 알려져 있습니다. Pass4Test의 Amazon인증 MLA-C01덤프는IT인증시험의 한 과목인 Amazon인증 MLA-C01시험에 대비하여 만들어진 시험전 공부자료인데 높은 시험적중율과 친근한 가격으로 많은 사랑을 받고 있습니다.
최신 AWS Certified Associate MLA-C01 무료샘플문제 (Q96-Q101):
질문 # 96
Case Study
A company is building a web-based AI application by using Amazon SageMaker. The application will provide the following capabilities and features: ML experimentation, training, a central model registry, model deployment, and model monitoring.
The application must ensure secure and isolated use of training data during the ML lifecycle. The training data is stored in Amazon S3.
The company is experimenting with consecutive training jobs.
How can the company MINIMIZE infrastructure startup times for these jobs?
- A. Use SageMaker managed warm pools.
- B. Use Managed Spot Training.
- C. Use the SageMaker distributed data parallelism (SMDDP) library.
- D. Use SageMaker Training Compiler.
정답:A
설명:
When running consecutive training jobs in Amazon SageMaker, infrastructure provisioning can introduce latency, as each job typically requires the allocation and setup of compute resources. To minimize this startup time and enhance efficiency, Amazon SageMaker offers Managed Warm Pools.
Key Features of Managed Warm Pools:
Reduced Latency: Reusing existing infrastructure significantly reduces startup time for training jobs.
Configurable Retention Period: Allows retention of resources after training jobs complete, defined by the KeepAlivePeriodInSeconds parameter.
Automatic Matching: Subsequent jobs with matching configurations (e.g., instance type) can reuse retained infrastructure.
Implementation Steps:
Request Warm Pool Quota Increase: Increase the default resource quota for warm pools through AWS Service Quotas.
Configure Training Jobs:
Set KeepAlivePeriodInSeconds for the first training job to retain resources.
Ensure subsequent jobs match the retained pool ' s configuration to enable reuse.
Monitor Warm Pool Usage: Track warm pool status through the SageMaker console or API to confirm resource reuse.
Considerations:
Billing: Resources in warm pools are billable during the retention period.
Matching Requirements: Jobs must have consistent configurations to use warm pools effectively.
Alternative Options:
Managed Spot Training: Reduces costs by using spare capacity but doesn't address startup latency.
SageMaker Training Compiler: Optimizes training time but not infrastructure setup.
SageMaker Distributed Data Parallelism Library: Enhances training efficiency but doesn't reduce setup time.
By using Managed Warm Pools, the company can significantly reduce startup latency for consecutive training jobs, ensuring faster experimentation cycles with minimal operational overhead.
AWS Documentation: Managed Warm Pools
AWS Blog: Reduce ML Model Training Job Startup Time
질문 # 97
A company plans to use Amazon SageMaker AI to build image classification models. The company has 6 TB of training data stored on Amazon FSx for NetApp ONTAP. The file system is in the same VPC as SageMaker AI.
An ML engineer must make the training data accessible to SageMaker AI training jobs.
Which solution will meet these requirements?
- A. Create an Amazon S3 bucket and use Mountpoint for Amazon S3 to link the bucket to FSx for ONTAP.
- B. Create a catalog connection from SageMaker Data Wrangler to the FSx for ONTAP file system.
- C. Mount the FSx for ONTAP file system as a volume to the SageMaker AI instance.
- D. Create a direct connection from SageMaker Data Wrangler to the FSx for ONTAP file system.
정답:C
설명:
Amazon SageMaker supports direct file system access for training jobs through Amazon FSx. AWS documentation states that FSx for NetApp ONTAP file systems can be mounted directly to SageMaker training instances when they are located in the same VPC.
Mounting the FSx file system allows SageMaker to stream large datasets efficiently without copying data into Amazon S3. This is ideal for very large datasets such as 6 TB of image data and avoids unnecessary storage duplication.
Options involving SageMaker Data Wrangler are intended for data preparation and exploration, not large- scale training data access. Mountpoint for Amazon S3 is not required and introduces additional complexity.
Therefore, Option A is the correct and AWS-aligned solution.
질문 # 98
A company stores historical data in .csv files in Amazon S3. Only some of the rows and columns in the .csv files are populated. The columns are not labeled. An ML engineer needs to prepare and store the data so that the company can use the data to train ML models.
Select and order the correct steps from the following list to perform this task. Each step should be selected one time or not at all. (Select and order three.)
* Create an Amazon SageMaker batch transform job for data cleaning and feature engineering.
* Store the resulting data back in Amazon S3.
* Use Amazon Athena to infer the schemas and available columns.
* Use AWS Glue crawlers to infer the schemas and available columns.
* Use AWS Glue DataBrew for data cleaning and feature engineering.
정답:
설명: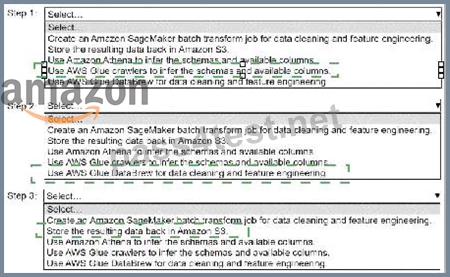
Explanation:
Step 1: Use AWS Glue crawlers to infer the schemas and available columns.
Step 2: Use AWS Glue DataBrew for data cleaning and feature engineering.
Step 3: Store the resulting data back in Amazon S3.
Step 1: Use AWS Glue Crawlers to Infer Schemas and Available Columns
Why? The data is stored in .csv files with unlabeled columns, and Glue Crawlers can scan the raw data in Amazon S3 to automatically infer the schema, including available columns, data types, and any missing or incomplete entries.
How? Configure AWS Glue Crawlers to point to the S3 bucket containing the .csv files, and run the crawler to extract metadata. The crawler creates a schema in the AWS Glue Data Catalog, which can then be used for subsequent transformations.
Step 2: Use AWS Glue DataBrew for Data Cleaning and Feature Engineering Why? Glue DataBrew is a visual data preparation tool that allows for comprehensive cleaning and transformation of data. It supports imputation of missing values, renaming columns, feature engineering, and more without requiring extensive coding.
How? Use Glue DataBrew to connect to the inferred schema from Step 1 and perform data cleaning and feature engineering tasks like filling in missing rows/columns, renaming unlabeled columns, and creating derived features.
Step 3: Store the Resulting Data Back in Amazon S3
Why? After cleaning and preparing the data, it needs to be saved back to Amazon S3 so that it can be used for training machine learning models.
How? Configure Glue DataBrew to export the cleaned data to a specific S3 bucket location. This ensures the processed data is readily accessible for ML workflows.
Order Summary:
Use AWS Glue crawlers to infer schemas and available columns.
Use AWS Glue DataBrew for data cleaning and feature engineering.
Store the resulting data back in Amazon S3.
This workflow ensures that the data is prepared efficiently for ML model training while leveraging AWS services for automation and scalability.
질문 # 99
An ML engineer needs to process thousands of existing CSV objects and new CSV objects that are uploaded. The CSV objects are stored in a central Amazon S3 bucket and have the same number of columns. One of the columns is a transaction date. The ML engineer must query the data based on the transaction date.
Which solution will meet these requirements with the LEAST operational overhead?
- A. Create a new S3 bucket for processed data. Set up S3 replication from the central S3 bucket to the new S3 bucket. Use S3 Object Lambda to query the objects based on transaction date.
- B. Create a new S3 bucket for processed data. Use AWS Glue for Apache Spark to create a job to query the CSV objects based on transaction date. Configure the job to store the results in the new S3 bucket. Query the objects from the new S3 bucket.
- C. Use an Amazon Athena CREATE TABLE AS SELECT (CTAS) statement to create a table based on the transaction date from data in the central S3 bucket. Query the objects from the table.
- D. Create a new S3 bucket for processed data. Use Amazon Data Firehose to transfer the data from the central S3 bucket to the new S3 bucket. Configure Firehose to run an AWS Lambda function to query the data based on transaction date.
정답:C
질문 # 100
A company has a Retrieval Augmented Generation (RAG) application that uses a vector database to store embeddings of documents. The company must migrate the application to AWS and must implement a solution that provides semantic search of text files. The company has already migrated the text repository to an Amazon S3 bucket.
Which solution will meet these requirements?
- A. Use an Amazon Textract asynchronous job to ingest the documents from the S3 bucket. Query Amazon Textract to perform the semantic searches.
- B. Use an AWS Batch job to process the files and generate embeddings. Use AWS Glue to store the embeddings. Use SQL queries to perform the semantic searches.
- C. Use a custom Amazon SageMaker notebook to run a custom script to generate embeddings. Use SageMaker Feature Store to store the embeddings. Use SQL queries to perform the semantic searches.
- D. Use the Amazon Kendra S3 connector to ingest the documents from the S3 bucket into Amazon Kendra. Query Amazon Kendra to perform the semantic searches.
정답:D
질문 # 101
......
Pass4Test의 Amazon인증 MLA-C01덤프를 구매하여 공부한지 일주일만에 바로 시험을 보았는데 고득점으로 시험을 패스했습니다.이는Pass4Test의 Amazon인증 MLA-C01덤프를 구매한 분이 전해온 희소식입니다. 다른 자료 필요없이 단지 저희Amazon인증 MLA-C01덤프로 이렇게 어려운 시험을 일주일만에 패스하고 자격증을 취득할수 있습니다.덤프가격도 다른 사이트보다 만만하여 부담없이 덤프마련이 가능합니다.구매전 무료샘플을 다운받아 보시면 믿음을 느낄것입니다.
MLA-C01시험대비 최신 덤프공부: https://www.pass4test.net/MLA-C01.html
- MLA-C01최신버전 시험대비 공부문제 ???? MLA-C01덤프최신버전 ???? MLA-C01인증시험 인기 시험자료 ???? 「 www.itdumpskr.com 」에서▶ MLA-C01 ◀를 검색하고 무료 다운로드 받기MLA-C01적중율 높은 시험덤프
- 최신 MLA-C01높은 통과율 공부자료 덤프공부문제 ???? ▛ www.itdumpskr.com ▟은▶ MLA-C01 ◀무료 다운로드를 받을 수 있는 최고의 사이트입니다MLA-C01시험대비 최신버전 자료
- MLA-C01높은 통과율 공부자료 인기시험 덤프자료 ???? ▶ www.exampassdump.com ◀웹사이트를 열고《 MLA-C01 》를 검색하여 무료 다운로드MLA-C01완벽한 인증시험덤프
- 시험대비 MLA-C01높은 통과율 공부자료 최신버전 덤프샘풀문제 다운 받기 ✏ 무료로 쉽게 다운로드하려면➤ www.itdumpskr.com ⮘에서( MLA-C01 )를 검색하세요MLA-C01적중율 높은 시험덤프
- MLA-C01덤프최신버전 ???? MLA-C01시험대비 덤프샘플 다운 ???? MLA-C01시험대비 최신버전 자료 ???? 지금{ www.passtip.net }에서《 MLA-C01 》를 검색하고 무료로 다운로드하세요MLA-C01유효한 공부자료
- MLA-C01시험패스 인증공부 ???? MLA-C01시험대비 덤프샘플 다운 ???? MLA-C01적중율 높은 시험덤프 ???? 검색만 하면[ www.itdumpskr.com ]에서▛ MLA-C01 ▟무료 다운로드MLA-C01최신기출자료
- MLA-C01높은 통과율 공부자료 인기시험 덤프자료 ???? ⏩ www.koreadumps.com ⏪을(를) 열고“ MLA-C01 ”를 검색하여 시험 자료를 무료로 다운로드하십시오MLA-C01덤프최신버전
- MLA-C01인증시험 인기 시험자료 ✏ MLA-C01시험패스 인증공부 ☔ MLA-C01최고품질 덤프문제 ???? 검색만 하면“ www.itdumpskr.com ”에서「 MLA-C01 」무료 다운로드MLA-C01높은 통과율 인기 덤프자료
- MLA-C01높은 통과율 공부자료 인기시험 덤프자료 ???? ⏩ www.dumptop.com ⏪을(를) 열고☀ MLA-C01 ️☀️를 검색하여 시험 자료를 무료로 다운로드하십시오MLA-C01최신버전 시험덤프문제
- MLA-C01최고품질 덤프문제 ???? MLA-C01퍼펙트 최신 공부자료 ???? MLA-C01최신기출자료 ???? 《 www.itdumpskr.com 》은▶ MLA-C01 ◀무료 다운로드를 받을 수 있는 최고의 사이트입니다MLA-C01합격보장 가능 시험덤프
- MLA-C01완벽한 인증시험덤프 ???? MLA-C01최고품질 덤프문제 ???? MLA-C01최신 업데이트 인증덤프자료 ???? ⏩ www.koreadumps.com ⏪을 통해 쉽게“ MLA-C01 ”무료 다운로드 받기MLA-C01최신덤프자료
- mollyqmzc458617.bloggazzo.com, bookmarking1.com, amieqdbf112218.bimmwiki.com, bookmarkbells.com, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, myportal.utt.edu.tt, keziaitkf378561.izrablog.com, bookmarkyourpage.com, haimarshd245899.tnpwiki.com, businessbookmark.com, sociallytraffic.com, Disposable vapes
참고: Pass4Test에서 Google Drive로 공유하는 무료 2026 Amazon MLA-C01 시험 문제집이 있습니다: https://drive.google.com/open?id=1KmAdqdWcD2rHi4aeSptQR-Zx611LvaAZ
Report this wiki page